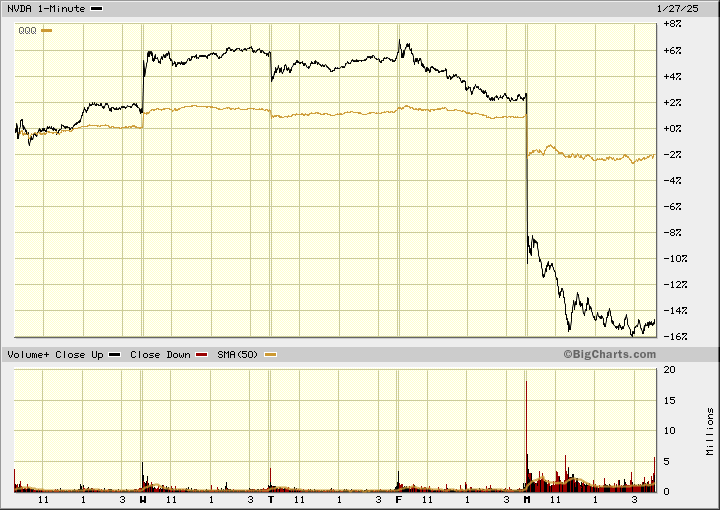
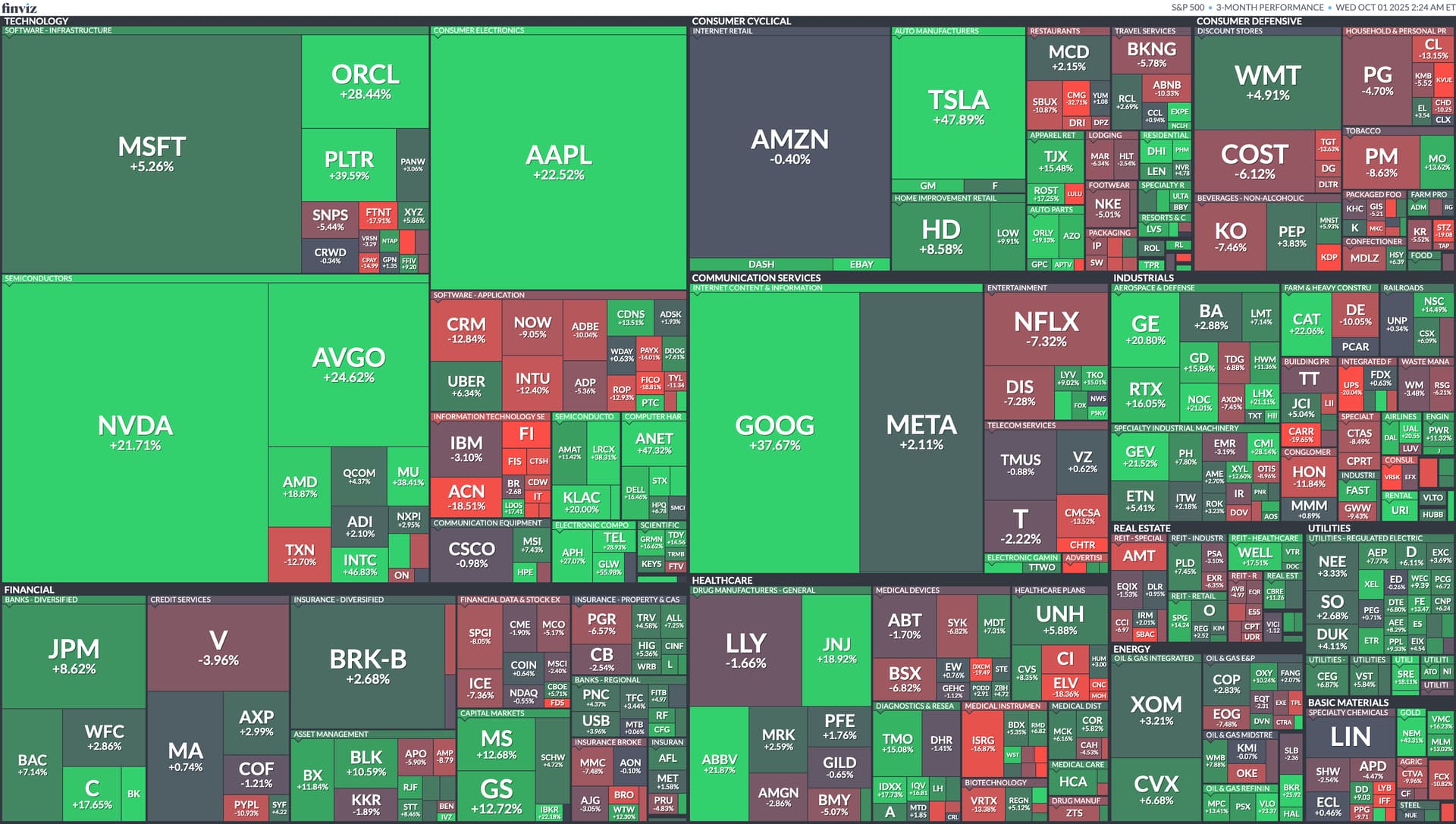
NVDA and the Nasdaq are way down today as news over the weekend of software (rather than hardware) improvements in AI technology. Some China AI firm put out their models publicly and they are both 1) really good, comparable to the best, and 2) apparently done using 2% of the hardware resources.
Perhaps the most extraordinary thing about this [revolutionary Chain-of-Thought (“COT”) models] approach, beyond the fact that it works at all, is that the more logic/COT tokens you use, the better it works. Suddenly, you now have an additional dial you can turn so that, as you increase the amount of COT reasoning tokens (which uses a lot more inference compute, both in terms of FLOPS and memory), the higher the probability is that you will give a correct response— code that runs the first time without errors, or a solution to a logic problem without an obviously wrong deductive step.
The first time I tried the O1 model from OpenAI was like a revelation: I was amazed how often the [python programming] code would be perfect the very first time. And that’s because the COT process automatically finds and fixes problems before they ever make it to a final response
The number of researchers showing up at the big research conferences like Neurips and ICML went up very, very dramatically. All the smart students who might have previously studied financial derivatives were instead studying Transformers, and $1mm+ compensation packages for non-executive engineering roles (i.e., for independent contributors not managing a team) became the norm at the leading AI labs.
a small Chinese startup called DeepSeek released two new models that have basically world-competitive performance levels on par with the best models from OpenAI and Anthropic… this model is absolutely legit, DeepSeek has made profound advancements not just in model quality but more importantly in model training and inference efficiency. Another major breakthrough is their multi-token prediction system. Most Transformer based LLM models do inference by predicting the next token— one token at a time. DeepSeek figured out how to predict multiple tokens while maintaining the quality you’d get from single-token prediction…One very strong indicator that it’s true is the cost of DeepSeek’s API: despite this nearly best-in-class model performance, DeepSeek charges something like 95% less money for inference requests via its API than comparable models from OpenAI and Anthropic. using pure reinforcement learning with carefully crafted reward functions, they managed to get models to develop sophisticated reasoning capabilities completely autonomously. This wasn’t just about solving problems— the model organically learned to generate long chains of thought, self-verify its work, and allocate more computation time to harder problems.
Expense ratio seems fine. I like the idea of picking stocks with low forward PE hoping they revert to the mean. A bit like value investing like Buffet would but instead of picking bargain stocks on fundamentals, you only select them based on recent deletion from index. I’m just not convinced that they’ll find enough winners (stocks about to rebound) among all the ones behind recently deleted and on their way further down. I cannot think of a similar ETF with longer track record than 6 month to know how well that strategy has done in various types of market conditions.
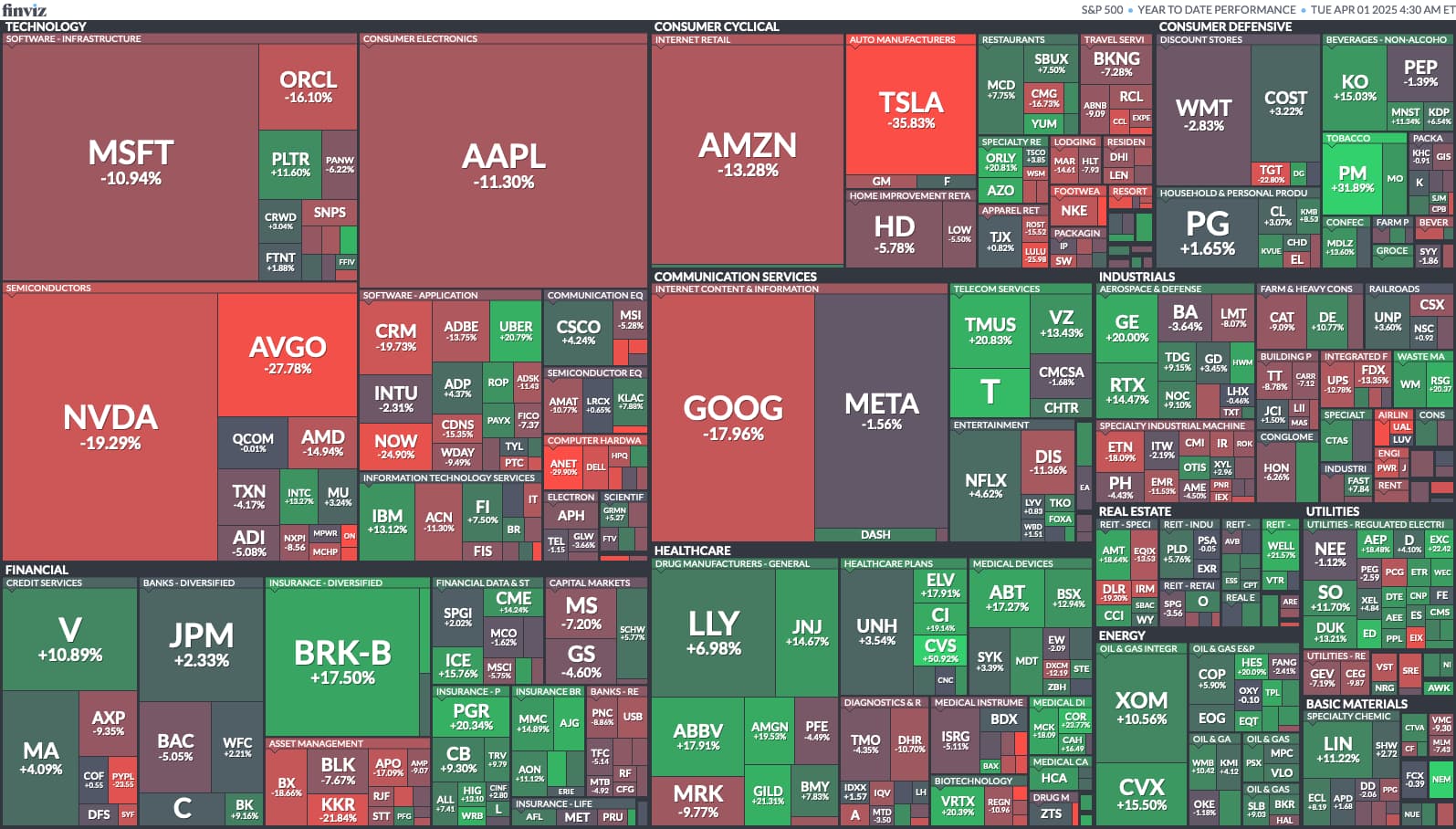
Q1 saw the Magnificent Seven as the biggest losers, as tech enthusiasm retreated. It was a tough start to the year for the stock market, at least the US markets (foreign ones at least were positive). Risk assets suffered, with Bitcoin the biggest loser recently, while safety plays did well and gold has continued to excel, and bonds beat cash as interest rate hikes seemed less likely.
ticker
type
Q1’25
GLD
gold
+19%
EFA
foreign (developed)
+8%
EEM
foreign (emerging)
+5%
BND
bonds
+3%
CPI
inflation (est)
+2%
JNK
junk bonds
+1%
USD
cash
+1%
PFF
preferreds
-1%
SPY
large caps
-4%
QQQ
tech
-8%
IWM
small caps
-10%
BTC
bitcoin
-12%
Q1 went pretty well, all things considered. But I’ve been investing in pretty obscure stuff lately, private equity and debt, etc, so that mostly did well and avoided the market drop. Wasn’t smart enough to own gold tho.
Notice that while the indexes were down meaningfully for US stocks, this is nearly all due to the ~1/3 weighting of those indexes these days to the Big Tech stocks. As you can see below, those stocks had double digit losses, while most of the rest of the market was slightly positive.
My BRK.B stake has done better than I hoped this past quarter, not complaining. Not sure it’s sustainable but that alone avoided me ending in the red for Q1.
Everyone’s a winner! Despite some initial volatility around Tariff Day in early April (when stocks dropped around -10% and fixed income saw modest losses as well), the trend has been back up. Trade fears turned out to be unfounded and the Negotiator-in-Chief did fairly well, ending up with bigger tariffs than before on other countries without much in the way of net retaliation. Still, a weaker dollar and shifting trends in equities saw foreign stocks in Europe and elsewhere outperform most US indexes (a relatively rare occurrence).
Themes around AI, quantum computing, and crypto drove tech and Bitcoin indexes to impressive gains, while fixed income languished with returns around inflation due to fears around unsound fiscal policy kept treasury rates on the higher side.
ticker
type
Q2’25
BTC
bitcoin
+25%
QQQ
tech
+17%
EFA
foreign (developed)
+11%
EEM
foreign (emerging)
+11%
SPY
large caps
+10%
IWM
small caps
+8%
GLD
gold
+5%
JNK
junk bonds
+3%
PFF
preferreds
+1%
USD
cash
+1%
CPI
inflation (est)
+1%
BND
bonds
+1%
Q2 went well for me, in part due to some of these crazy crypto stocks, a trend were microcap shell companies are taken over by a large group of crypto investors and set to hoarding some coin or another ala MicroStrategy’s original BTC treasury approach. The market seems willing to pay $2-3 for a crypto coin held in a company, instead of just $1 for the coin in the crypto markets. Unsurprisingly, this mismatch has lead to quite a number of such crypto-transitions by companies hoping to increase their valuations.
Gold has really shined as markets have become more skeptical of the US’s fiscal responsibility (look - a shutdown!) and the prospects of future rate cuts has made gold more attractive on a relative basis. Enthusiasm for risky stocks such as small caps and emerging markets has been strong this quarter, especially in the junkier or highly shorted stocks, and all of these overtook their larger peers. Still, there were gains all around, just a question of how much:
ticker
type
Q3’25
GLD
gold
+17%
IWM
small caps
+12%
EEM
foreign (emerging)
+11%
QQQ
tech
+9%
BTC
bitcoin
+8%
SPY
large caps
+8%
PFF
preferreds
+5%
EFA
foreign (developed)
+4%
JNK
junk bonds
+2%
BND
bonds
+2%
USD
cash
+1%
CPI
inflation (est)
+1%
Q3 went well for me, although many of my trading and crypto-stock gains were given back on a really terrible short squeeze in a china fraud stock QMMM that ran up from $7 to $300. It was last seen around $100 and halted by the SEC pending delisting. Sadly most of my losses were already realized, but it will be nice to get back a little bit when it reopens in a few weeks at a few bucks.
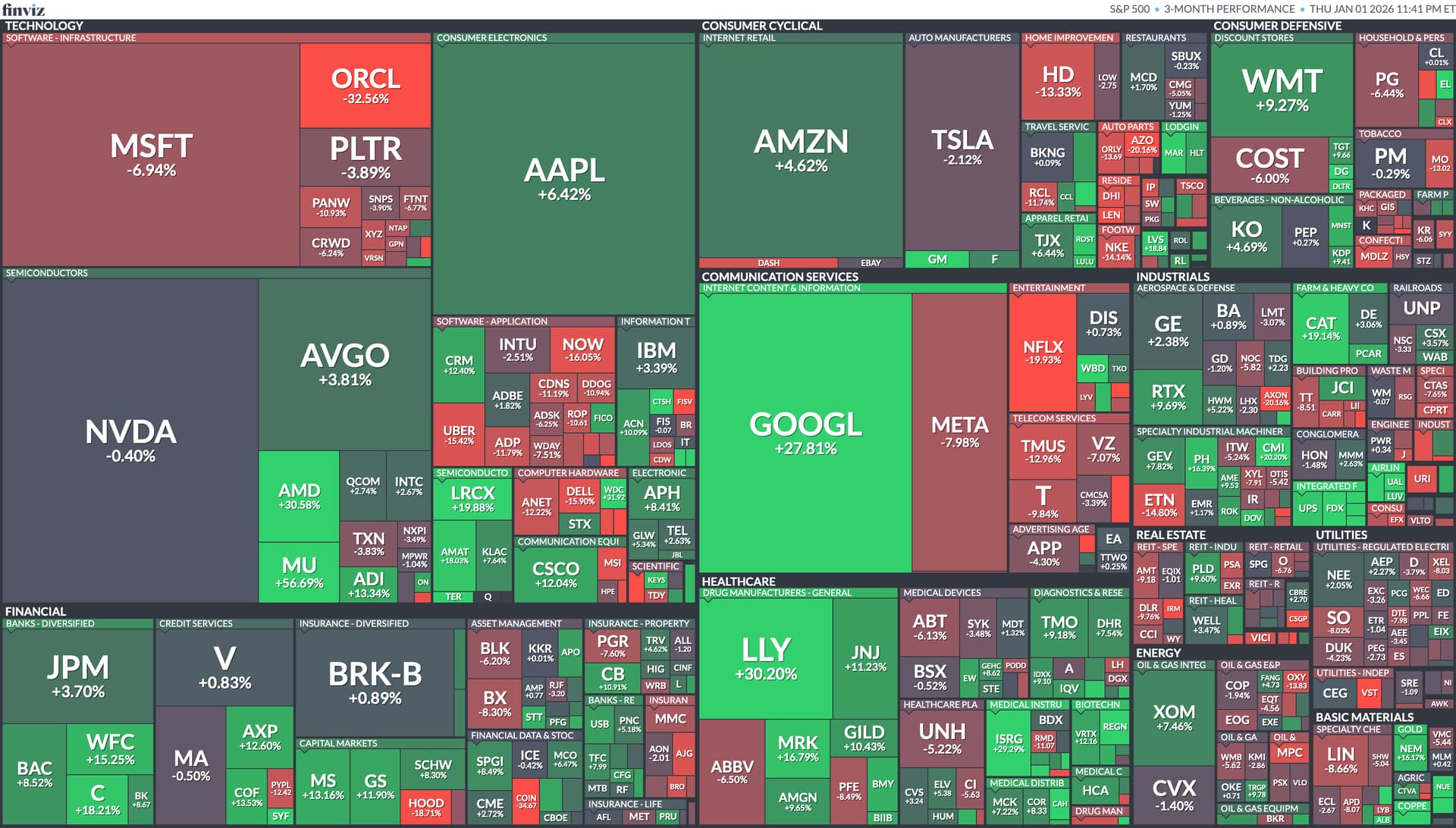
Gold continued to outperform everything, with fiscal responsibility a dim hope in Washington and prospects of future rate cuts making gold more attractive on a relative basis. Stocks were muted but still performed well with moderate gains across all sectors. Bitcoin and the crypto markets suffered a significant bear market, losing a quarter of their value off the highs earlier this year.
ticker
type
Q4’25
GLD
gold
+16%
IWM
small caps
+5%
EFA
foreign (developed)
+5%
QQQ
tech
+4%
SPY
large caps
+4%
EEM
foreign (emerging)
+3%
JNK
junk bonds
+1%
BND
bonds
+1%
USD
cash
+1%
PFF
preferreds
+0%
CPI
inflation (est)
-0.3%
BTC
bitcoin
-25%
Q4 went well for me, with no major disasters on the active trading front, although irritatingly that china scam QMMM remains halted months later since the executives all fled and no one turned out the lights to allow the stock to trade over-the-counter.
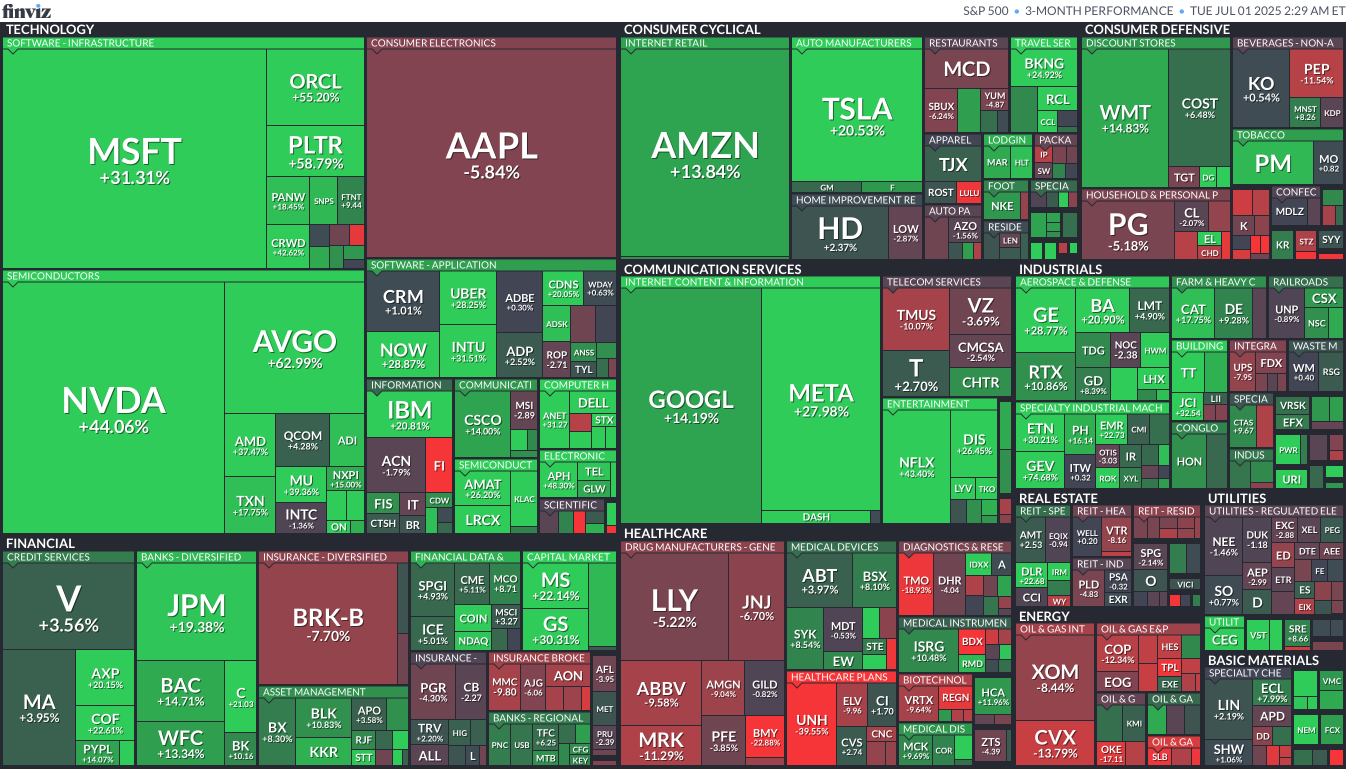
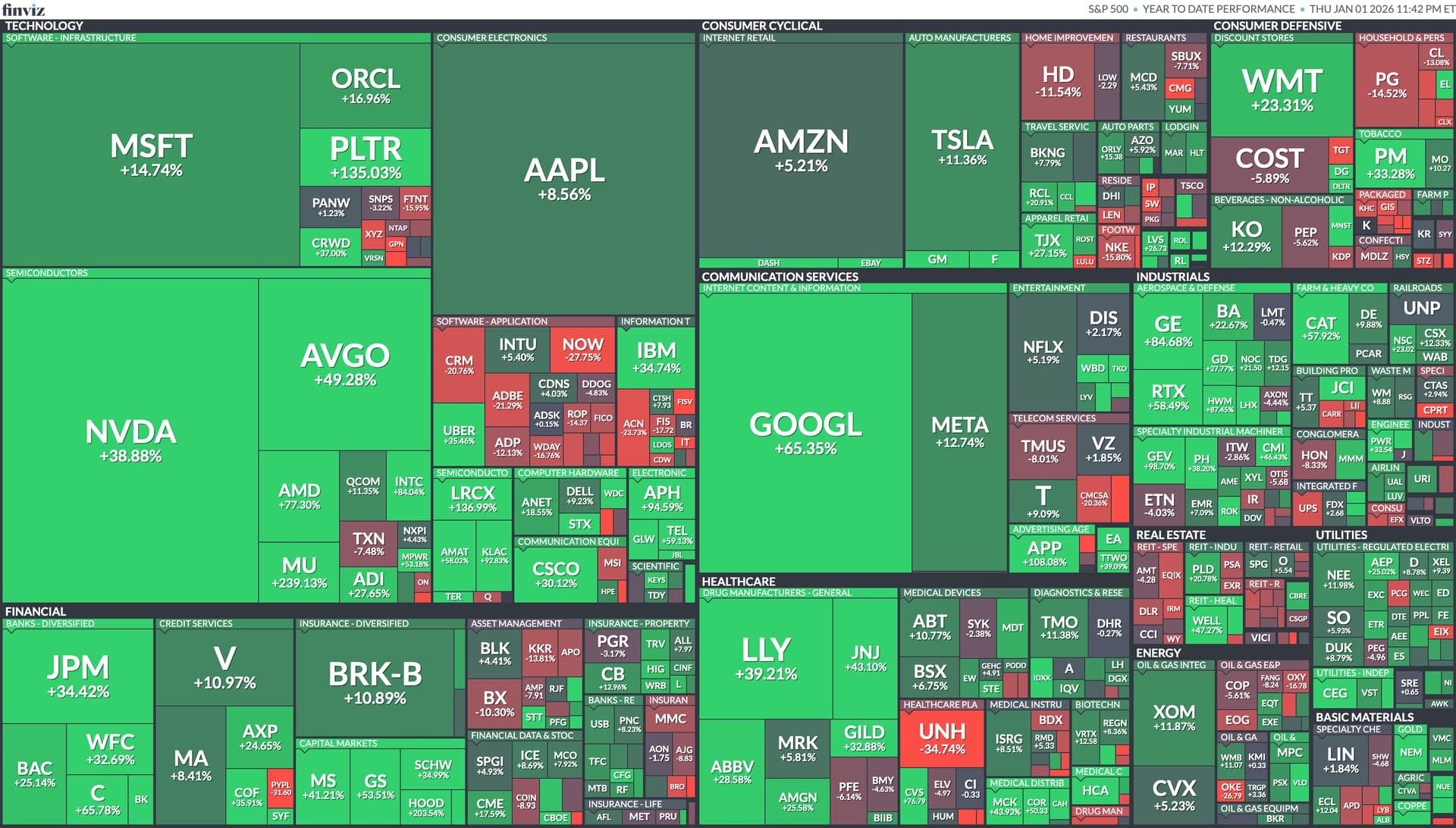
Here are the 2025 yearly numbers. Huge win for gold, although both stocks and bonds did well relatively speaking. Foreign stocks outperforming US stocks (after years of lagging), and fixed income did well as inflation was relatively low and interest rate cuts helped boost existing bonds. Bitcoin was down modestly after their huge gains in 2024 (over +100% then, now -10% since).
ticker
type
2025
GLD
gold
+62%
EEM
foreign (emerging)
+33%
EFA
foreign (developed)
+31%
QQQ
tech
+23%
SPY
large caps
+19%
IWM
small caps
+18%
JNK
junk bonds
+8%
BND
bonds
+7%
PFF
preferreds
+5%
USD
cash
+4%
CPI
inflation (est)
+2%
BTC
bitcoin
-10%
Annual 2025 winners, noting those big green squares for Big Tech and AI related stock (GOOG, NVDA).
Market has been pretty nutty lately and we’re about to get the big one.
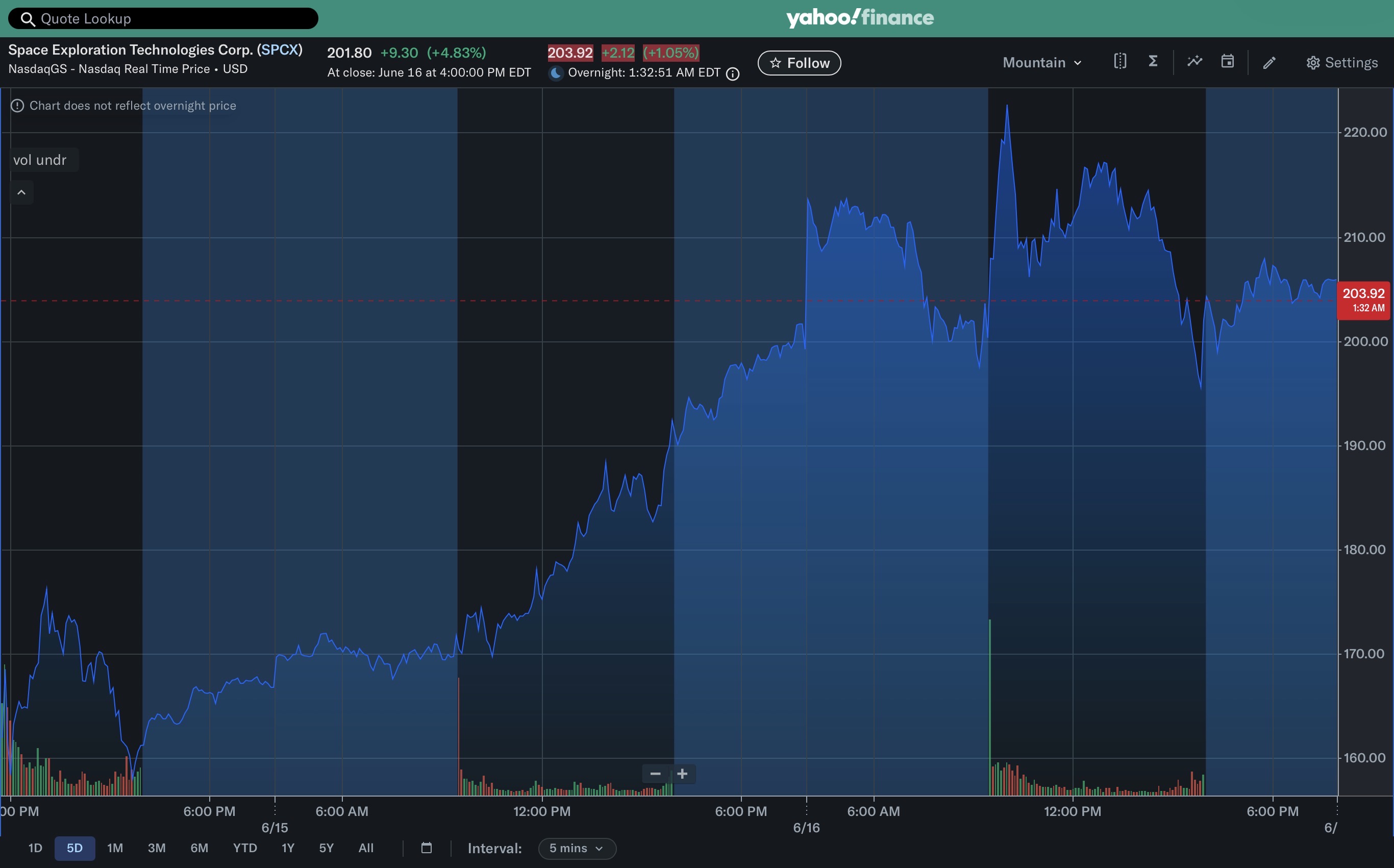
SpaceX is planning a $75 billion IPO at $135 per share that would value Elon Musk’s rocket company at $1.75 trillion—likely making it the largest public offering in history. The stock is set to debut on the NASDAQ on June 12.
SPCX ipo shares are being offered to retail at many brokers - Fidelity, Schwab, Robinhood. If they’re offering, so you really want them?
Hard pass. Historically, waiting a few months is usually a safer bet for most IPOs. I’d say that’s likely applicable to the SpaceX IPO considering the S-1 information I read. TAM of 3 times the size of the global food industry seems questionable to me. At $1.75T evaluation, the base 95x price-to-sales multiple is unreal high. Even assuming the deals with google and anthropic actually pan out, that puts forward P/S at 35x. That’s still very high for something that’s not guaranteed. So basically SpaceX only makes sense to me at this price if the AI gravy train continues at this pace for a few years.
I’m good with how my index ETFs are gonna buy some anyway so won’t consider any extra.
SPCX at $200 in just a few days is up around +30% from the ipo’s opening price, ie where you could have bought at $150, and around +50% from the ipo’s actual price of $135.